Joint Unsupervised Depth-Estimation and Obstacle-Detection from Monocular Images
Inspired by J-MOD² by Mancini et al. and my previous paper on depth estimation I wanted to go back and re-join depth estimation and obstacle detection in a single network. In the process I not only beat the SOTA for unsupervised monocular depth estimation but also introduced some really cool loss functions and a way to train a model to segment obstacles without ground truth data. Fun stuff, I promise!
Basics of Unsupervised Depth Estimation
While in my first paper I still used supervised learning to train my model for depth estimation, this time I tried to go for un- or self-supervised learning for my training. The basic method to do that is to estimate the depth for an image, then transform this image to a second perspective considering the estimated depth, and then treat the difference between the transformed image and the real image from that perspective as a loss.
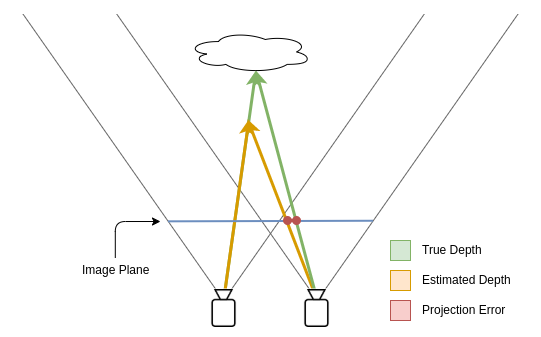
Even if the depth is very wrong at first, in order to minimize the loss, the model will try to estimate the correct depth. In order to get state-of-the-art results it was necessary to add some more losses to the model e.g. to enforce smoothness of the surface and to account for some issues with this approach. Finally I needed to balance those losses correctly and to find the right training strategy for the model. If you want to know all the details of that you can find a link to the paper at the bottom of the page.
Basics of Self-supervised Obstacle Segmentation
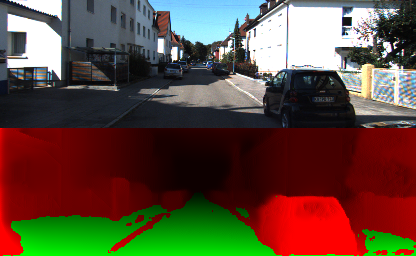
Once you have a model that predicts a pretty good depth what do you do? You build on the success and try to make it useful. I did that by using the depth to try and predict if an area is drivable or not. I created a function that computes the inclination and roughness of the predicted depth and based on some simple heuristic decides whether the area is in fact drivable or not. Even though the heuristic is simple, this process of computing the inclination and roughness is relatively expensive computationally.
What if we could replace this expensive operation by a single additional layer in the neural network? I tried it out and added a layer that I trained together with the depth network and was shocked to find out that not only the obstacle prediction worked, but it produced better looking results than my simple heuristic with much fewer holes and better semantic correlation.
So what happened to the depth estimation branch with this additional requirement to the network?
Did it get worse because it had to "focus" on obstacle segmentation as well?
On the contrary! The model with obstacle segmentation branch was actually significantly better than
the model without it. This was a huge surprise!
Have a look at some results from the test set:
If you're interested, here's full paper as PDF.
If you're also interested in the code feel free to drop me a mail.
If you would like to use this work please cite me!🙂
@misc{pisoni2019judo,
title={Joint Unsupervised Depth-Estimation and Obstacle-Detection},
author={Raphael Pisoni},
year={2019},
note={\url{https://rpisoni.dev/JUDO_Net.pdf}},
}