Hackathon: Diagnosing COVID-19 with X-Rays and Transfer Learning
In the early days of COVID-19, before there were cheap PCR and Antigen-Tests, one way to diagnose it was through a CT-Scan. The obvious drawbacks of this were of course that CT-Scans are pretty expensive, they are not equally available in all parts of the world and that they deliver quite a high dose of radiation.
In March 2020 Esther Schaiter and me heard about a 24hour online hackathon with the goal to surface ideas to combat problems related to COVID-19. Since Esther was a final year medical student she was very close to the issue. Therefor we decided to tackle the idea of diagnosing COVID with X-rays.
Soon we found out that at the time only ~130 X-rays of COVID patients were available. This was less than ideal. So in order to give our model a chance we gathered every chest X-ray dataset that we could find, combined them and pretrained the model on that data. See the results below:
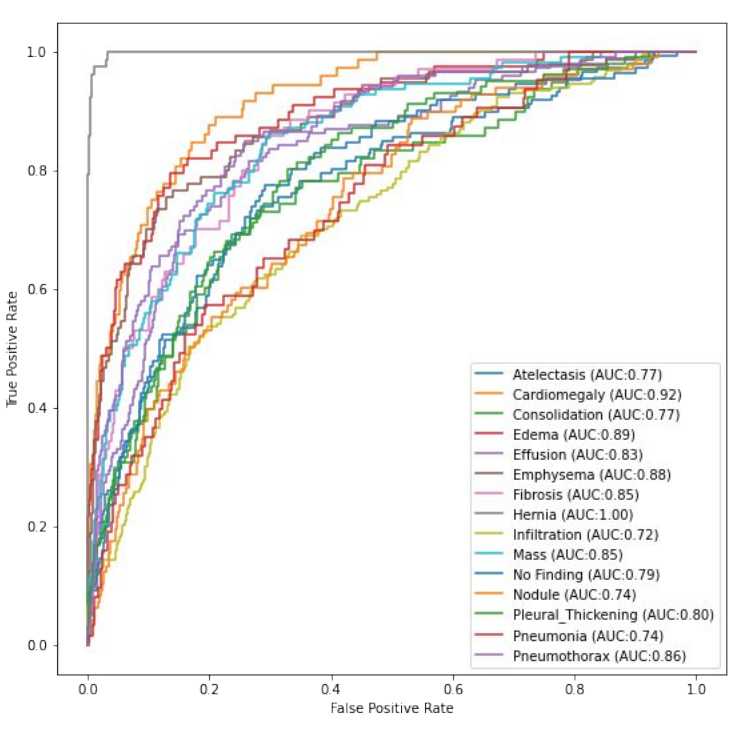
So in the next stage we used the model that had already learned a lot about chest X-rays and fine-tuned it to recognize the things that we were actually interested in. Namely, we divided our COVID-19 dataset into 4 classes:
- COVID-19
- Common Pneumonia (looks similar to COVID-19)
- Other Diagnosed Condition
- No Finding / Healthy patient
After we trained on this dataset the results looked like this:
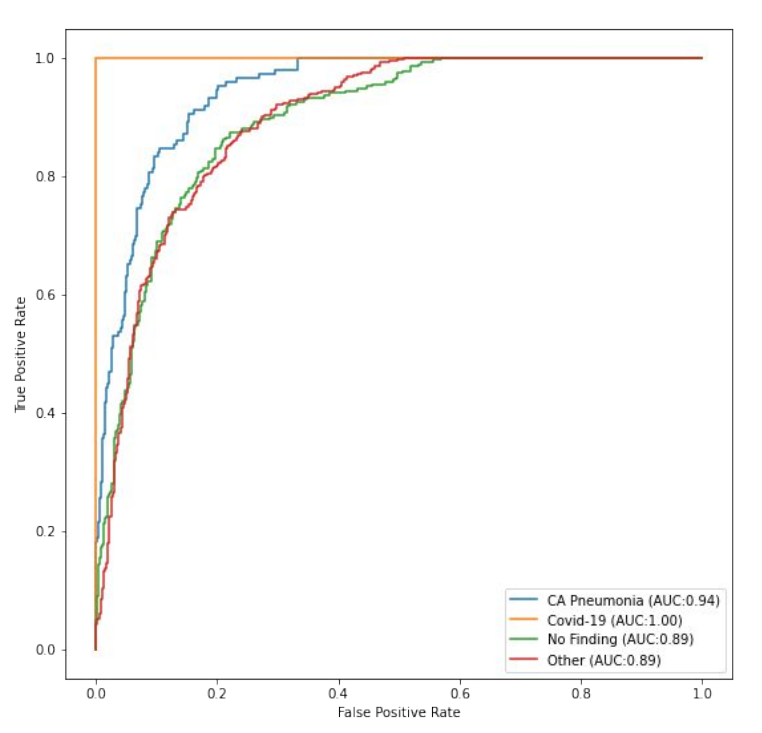
As one can see all curves looked good but the Area under the Curve value for COVID-19 was a perfect 1.0 which seemed very implausible. Soon we realized that we had committed the worst crime of data science, namely not looking at the data enough.
We had not been aware of the fact that for some patients there were multiple X-rays in the COVID dataset to represent the illness at multiple stages. By splitting the dataset into training and test-set randomly we ended up with different images from the same patient in both sets. The meaning of this was that in some sense we were evaluating on the training set.😱
This would have been a fixable error but unfortunately the 24 hours were almost over, and we did not have time to retrain the model. So all we could do was to present the results like this, mentioning their flaws.
What we learned from this hackathon was that even under time pressure the most important thing is to try to understand the data as good as possible. Adding large amounts of data is useless if you don't know exactly what it contains. And even if you do, understanding the implications is sometimes hard.